Investigating Generalizability of Speech-based Suicidal Ideation Detection Using Mobile Phones
Abstract
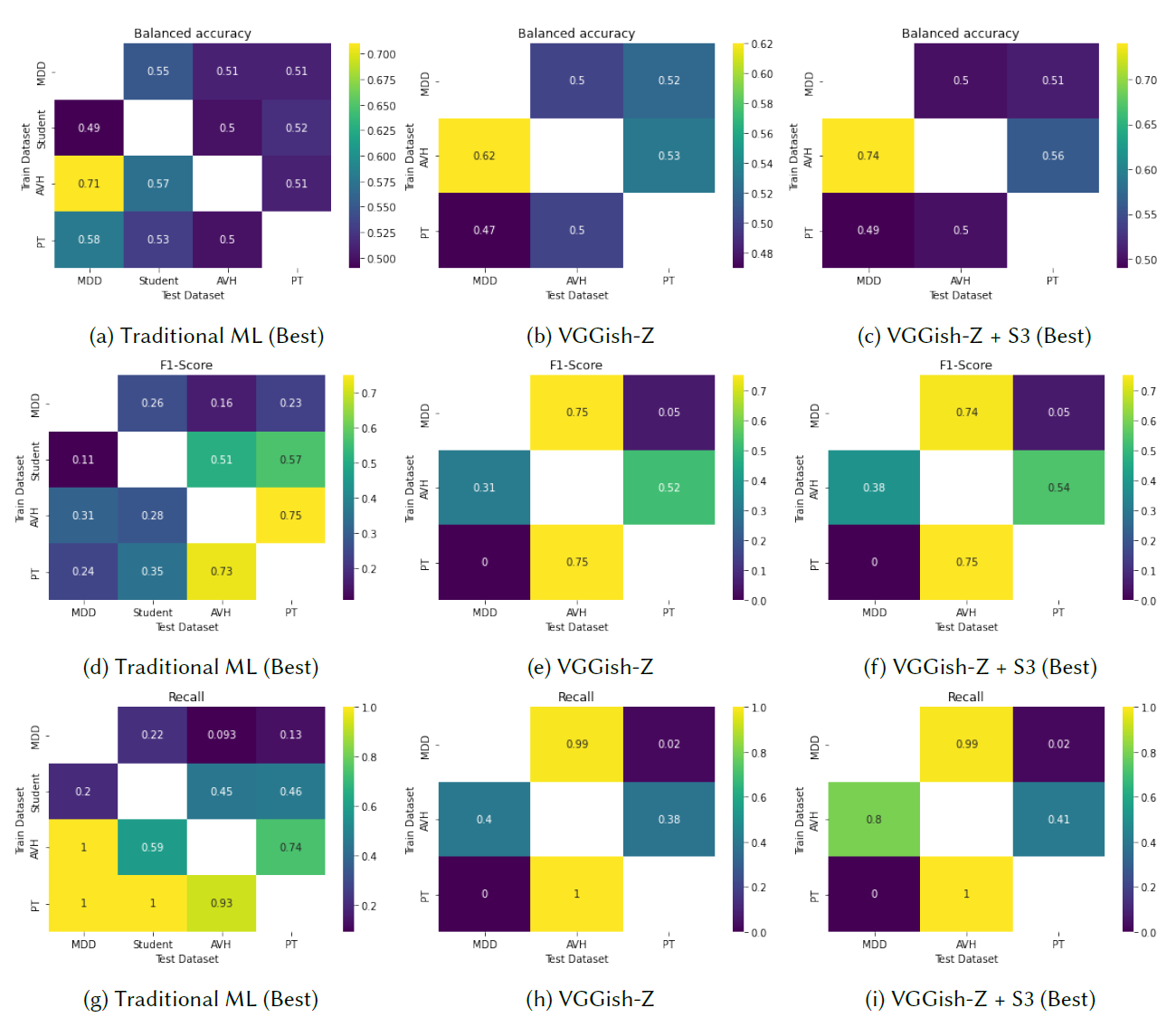
Speech-based diaries from mobile phones can capture paralinguistic patterns that help detect mental illness symptoms such as suicidal ideation. However, previous studies have primarily evaluated machine learning models on a single dataset, making their performance unknown under distribution shifts. In this paper, we investigate the generalizability of speech-based suicidal ideation detection using mobile phones through cross-dataset experiments using four datasets with N=786 individuals experiencing major depressive disorder, auditory verbal hallucinations, persecutory thoughts, and students with suicidal thoughts. Our results show that machine and deep learning methods generalize poorly in many cases. Thus, we evaluate unsupervised domain adaptation (UDA) and semi-supervised domain adaptation (SSDA) to mitigate performance decreases owing to distribution shifts. While SSDA approaches showed superior performance, they are often ineffective, requiring large target datasets with limited labels for adversarial and contrastive training. Therefore, we propose sinusoidal similarity sub-sampling (S3), a method that selects optimal source subsets for the target domain by computing pair-wise scores using sinusoids. Compared to prior approaches, S3 does not use labeled target data or transform features. Fine-tuning using S3 improves the cross-dataset performance of deep models across the datasets, thus having implications in ubiquitous technology, mental health, and machine learning.